
This 4-part blog series aims to provide an overview of deserialization vulnerabilities in .NET, using C# as the primary language. While explaining the serialization/deserialization and the corresponding vulnerabilities, I have used the BinaryFormatter deserializer, which is inherently unsafe for deserialization and hence more susceptible to deserialization attacks.
The 4 parts of the series convey information as follows:
- Part 1 - Explains what is an object in memory. After that, it builds on this understanding to explain why there is a need for serialization and deserialization.
- Part 2 - Explains the serialization and deserialization process via BinaryFormatter in detail. It also gives you insights into the content of the serialized payload and how to understand the same.
- Part 3 - Uses ysoserial to create a malicious payload. It leverages understanding from the previous parts to demonstrate and explain a deserialization attack.
- Part 4 - Discusses various preventive measures that we can take to ensure secure deserialization.
Storage of an object in memory
In .NET, the CLR manages the allocation and destruction of objects. The memory management in .NET involves storing data on the stack or heaps. The 4 different types of heaps maintained by the CLR include the code heap, small object heap (SOH), large object heap (LOH) and the process heap.
Objects in the heap memory are not stored in a contiguous memory block with all information at one place. Instead objects are stored as interconnected graphs. For example consider the class:
[Serializable]
public class Demo
{
public string ApplicationName { get; set; } = "Akash application data";
public int ApplicationId { get; set; } = 1001;
}
On creating an object of the above class, we can use windbg to inspect its presence in memory. As a reference type, it will be created in the heap (specifically in the SOH). Running !dumpheap reveals the object:

Clicking on the MT column shows us the details of the object we created:
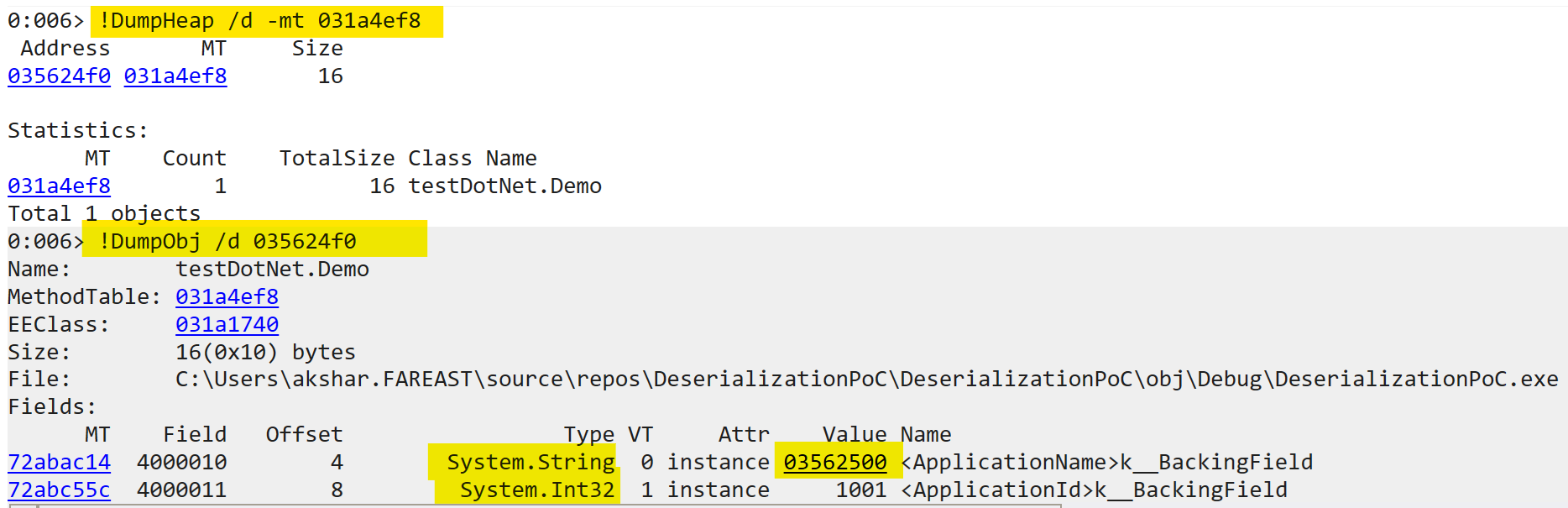
The demo object contains a string (ApplicationName) and an int (ApplicationId). The primitive type int, ApplicationId, gets stored directly in the object’s memory block. But for ApplicationName which is a reference type (string), only the reference is stored in the demo object. The reference points to the memory location where the string Akash application data is actually stored. Going to that address (03562500), shows us the string value:
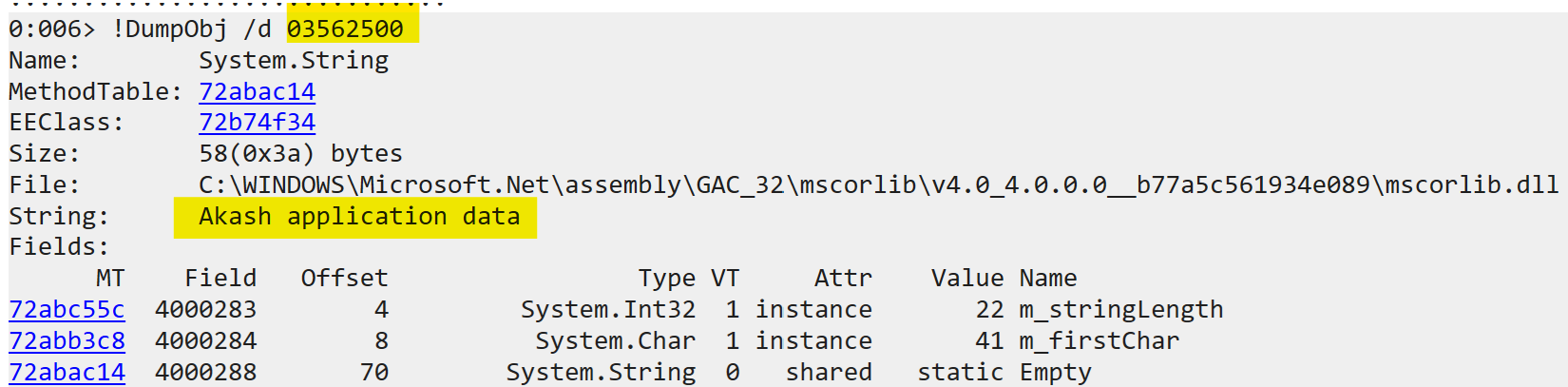
This illustrates that an object’s content may be stored in non-contiguous chunks in memory.
Need for deserialization and serialization
In application development, scenarios often require sharing information between servers, writing data from memory to disk, or efficient transportation. In multiple such situations, there is a need to collect all information about an object (from its object graph in memory) into a form such that it can be efficiently stored/transported. Serialization is the process of converting data in an object graph in memory into a serialized stream.

Deserialization, the reverse process, involves recreating the object in memory from the serialized data.

Just like any other protocol, the program deserializing the serialized data must correctly interpret it to recreate the object graph. This requires defining a format into which the data can be serialized and from which it can be deserialized. There are several formats that you can use for serialization/deserialization based on the different deserializers/searializers. Some of them are binary, json, xml, etc.
Some frequently encountered use cases of serialization and deserialization
Building on the insights provided above, you might be pondering why you’ve never had to implement serialization and deserialization yourself. This is largely due to the fact that many libraries handle these processes internally. A prime example is the System.Net.Http library, which is often used to instantiate objects like HttpClient for making HTTP requests and handling responses. These libraries inherently manage the serialization of your request data into a JSON data stream. Additionally, they facilitate the deserialization of the response stream into a string or JSON object. Thanks to this automated handling, even when dealing with scenarios involving data transport, you’ve likely been spared from writing explicit serialization and deserialization code.
The next blog will dive deep into serialization and deserialization via binary formatter, laying the groundwork for understanding the vulnerabilities in the deserialization process.