
Note: Prior to proceeding further, it is highly advisable to familiarize yourself with Part 1 which discusses object storage in memory, provides a practical demonstration using Windbg, explores the need for serialization and deserialization, delves into understanding object content, and introduces the basics of serialization and deserialization processes in the .NET environment.
Part 2 delves into the intricacies of how the Binary Formatter serializes and deserializes data, following the groundwork laid in Part 1. That way, you no longer need to look at the process of serialization and deserialization as a black box. There are various other serializers/deserializers that can be used for a similar purposes. We specifically consider binary formatter as it’s inherently insecure and learning more about it will help us understand the crux behind deserialization vulnerabilities.
We will also look at the serialized data created by the binary formatter. Understanding this gives us insights into the content of the serialized payload, which aids in understanding how one can generate a malicious serialized payload.
Overview of the serialization and deserialization process
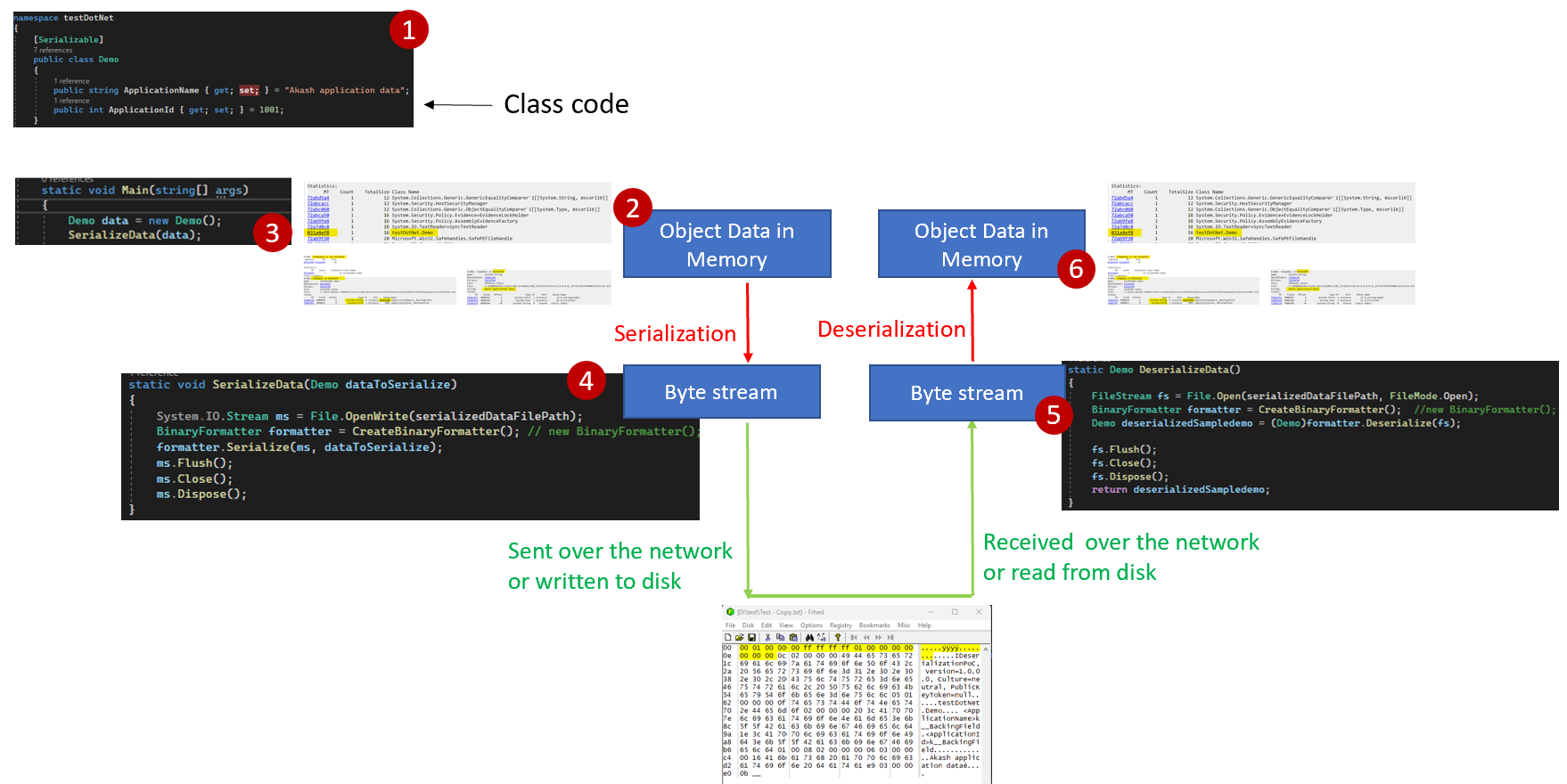
Continuing with the class introduced in Part 1, (1) in the image below showcases the code for the same class .
In (3) we create an instance of the demo class which is stored in heap memory as an object graph. The last line in (3) also calls the serialization function that can be seen in (4). Post the completion of the serialization process using the binary formatter we end up with the binary byte stream which can then be transported over the network to a different server, sent to another service or stored on disk for later retrieval.
In (5) this data is received at the other end/ read back from the disk and we deserialize the stream to create the objects in memory. Here the process deserializing the data may or may not be the same as the one that serialized the payload and hence may or may not have independent address spaces. The memory snips from windbg in (2) and (6) are just for illustration.
Note: Zoom into images for clarity
Looking at the serialized payload
As highlighted in Part 1, serialization and deserialization utilities must adhere to a standard when processing the serialized payload. For the process of binary serialization, this format/standard is specified in open specification documents that can be downloaded from here
In this blog post, we will dissect the binary serialized payload generated by the binary formatter. Broadly, the binary payload can be envisioned as a compilation of records, each consisting of a header indicating the record type followed by the data within the record.
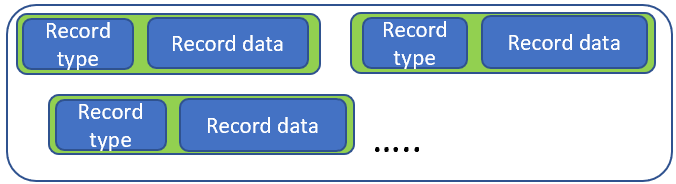
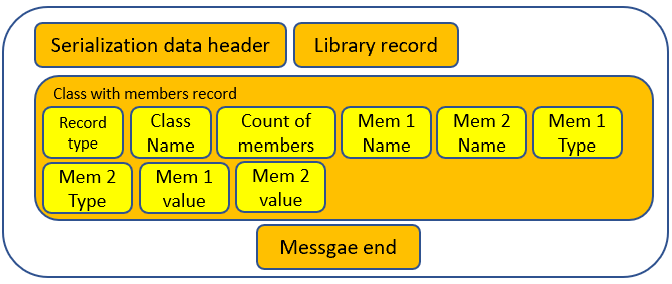
Taking a more detailed view, the critical records constituting the payload are outlined below. The payload commences with the serialization data header, encapsulating details such as the binary formatter version, etc. Subsequently, we encounter the library header, furnishing information about the assembly containing the serialized type. This is succeeded by details about the serialized object, encompassing its type name and comprehensive information about its member types — their names, types, and the respective values.
The serialized binary data specific to our class is presented below:
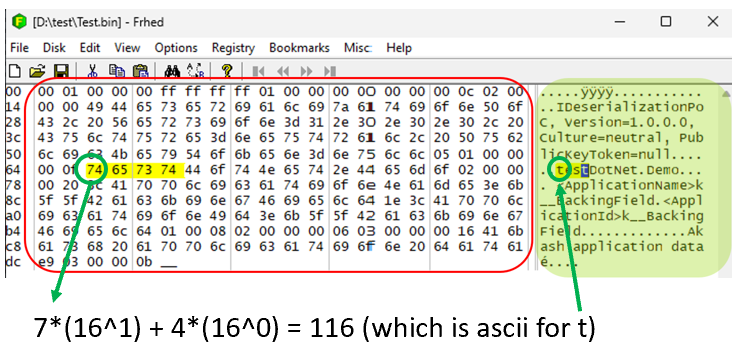
The data is represented in hex within the red boundary, with the ASCII representation displayed in green. As an illustrative example, let’s consider the circled part in green. The initial string “74” is denoted in Hex. This signifies 8 bytes in total (4 bytes to represent 7 and 4 bytes for 4). It’s important to note that we adhere to little-endian notation. Therefore, 74 translates to 7(16^1) + 4(16^0) = 116 (ASCII for ‘t’). The first column in the figure denotes line numbers, and the actual data is within the red area.
For those keen on a comprehensive understanding of the payload content, a deep dive into this blog is recommended. The blog explains the significance of different bytes, showcasing the serialized payload for a similar class.
Additionally, we share a payload featuring a hierarchy of objects. In this scenario, the demo class encompasses an additional member storing another object of the class internalObj. Both the class code and the corresponding serialized payload are provided below.
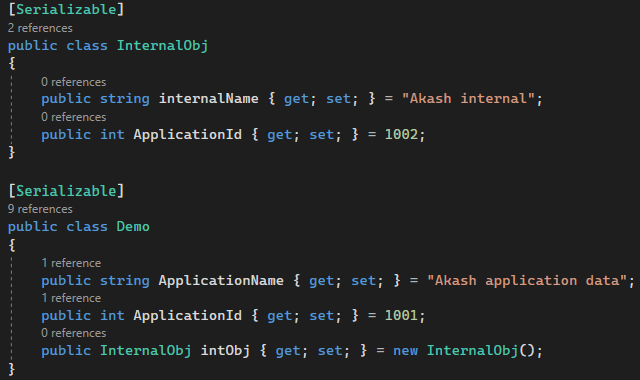
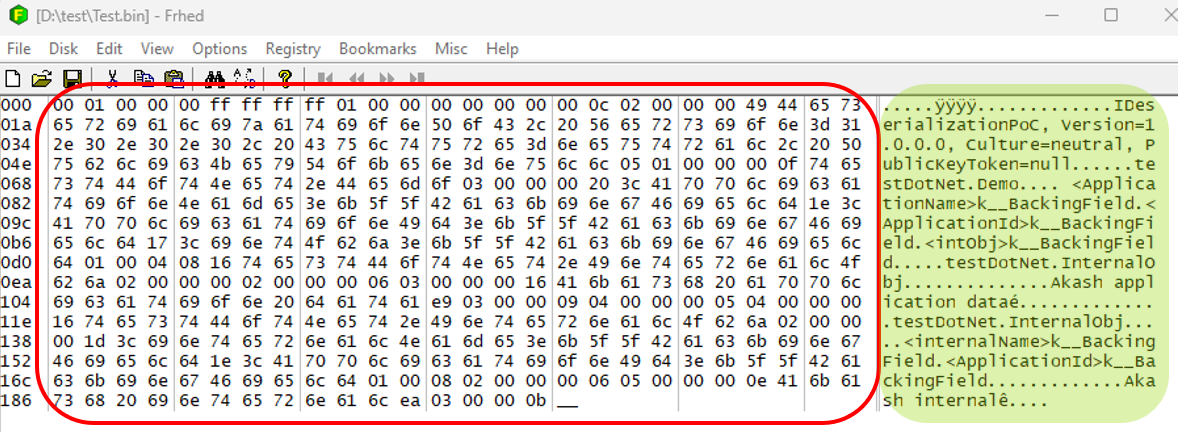
A key observation in the aforementioned payloads is the inclusion of the serialized object’s type information (e.g., testDotNet.Demo, testDotNet.InternalObj). During deserialization, the binary formatter utilizes this data to ascertain the type of object to be instantiated by extracting it from the serialized payload stream. Notably, this characteristic introduces inherent vulnerabilities to the binary serializer. The intricacies behind this vulnerability will be unravelled and expounded upon in the forthcoming Part 3, inviting you to delve deeper into the intricacies of the subject.
Customizing the binary formatter serialization/deserialization process
Before delving into the intricacies of the binary formatter’s serialization and deserialization flow, it’s beneficial to explore various customization approaches supported by the binary formatter. You can refer to the insightful blog post available at Binary Serialization (diranieh.com)
A concise summary of the blog (although recommended to read blog for a comprehensive understanding): To enable the binary formatter to handle serialization and deserialization for an object type, mark the object as serializable using the [Serializable] annotation. This annotation can also be applied to properties and members. In simpler scenarios, the binary formatter seamlessly manages the serialization process. However, if you wish to define custom serialization/deserialization behavior, consider implementing the ISerializable or IDeserializationCallback interfaces. In instances where annotating a class as serializable is not feasible, such as when dealing with a class in an external assembly, or if you prefer writing custom serialization/deserialization logic outside the class to be serialized/deserialized, you can create a surrogate class for it. This surrogate class allows you to define specialized logic for serializing and deserializing the original class. For a detailed exploration of these concepts, please refer to the aforementioned blog.
Another avenue for customization is through binders, offering the flexibility to implement custom methods like BindToName and BindToType. These methods seamlessly integrate into the binary formatter’s serialization process. Specifically, BindToName takes the object type as input and expects corresponding type and assembly names as string outputs. These outputs are then incorporated into the serialized stream, which contains information about the type of object being serialized and its assembly. Conversely, BindToType reverses this process (during deserialization) by returning the object type based on the provided name of the type and its assembly, that are passed to it as string inputs. These customization techniques empower developers to tailor the serialization process to meet specific requirements.
Serialization flow via binary formatter
In this section, I provide a detailed exploration of the serialization flow in the Binary Formatter by analyzing the code within the .NET framework. This analysis focuses on scenarios where the class of the object is marked as serializable using the [Serializable] annotation. It’s worth noting that there are alternative methods to specify custom behaviors or functions during serialization/deserialization, such as defining a surrogate or implementing the ISerializable interface. For the purpose of this explanation, we do not employ the binder during serialization/deserialization.
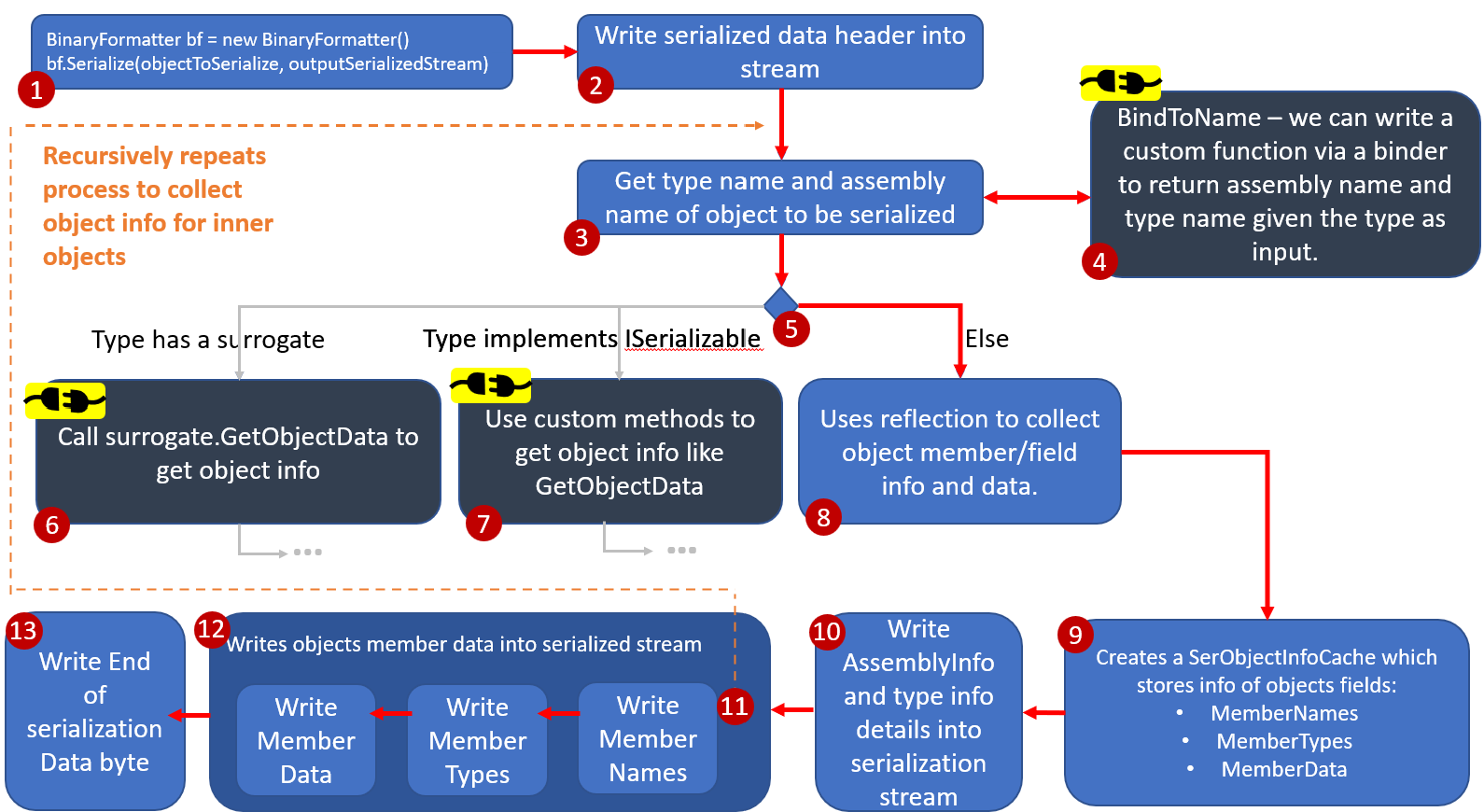
(1) marks the initiation of the binary formatter and the serialization call included by developers in their code. Following this, the process of serializing the object begins, writing the corresponding serialized binary payload into the output stream (referred to as outputSerializedStream in (1)). The initial segment of the payload comprises a serialization header containing information about the binary formatter’s version, etc., which is written into the output stream in (2).
In (3), we get the name of the assembly that contains the object we are deserializing and also the object type.
If desired, you can customize the type written into the serialized payload instead of the actual type being serialized by using a binder that can be pass as input in the new BinaryFormatter() call. This involves implementing the BindToName method, which takes the type as the input param and returns the same type or a type of your choice in the string format, which is then written into the stream (so this gives control over what type is written into the stream). A similar level of control is available during deserialization using the BindToType method. The BindToType function takes the type name (read in string form) from the serialized stream as input, and returns the type object of the type be instantiated by the binary formatter. Examples use cases of these methods are discussed in this stackoverflow question.
At (5), the .NET code checks for the presence of a surrogate or the implementation of the ISerializable interface to handle the serialization/deserialization of the object. In our case, with neither of these methods employed, the code utilizes reflection at (8) to gather information about the object’s fields, their types, and values. This information is stored in a SerObjectInfoCache as depicted in (9).
The subsequent steps involve writing the information about the assembly and the object being serialized into the serialization output stream. Post that, as shown in (12), all names, types and data of each member type are written into the serialization stream. Notably, if there are nested objects within the primary object being deserialized, as illustrated in (11), the information of these internal objects is recursively extracted and written to the stream.
Deserialization flow using binary formatter
This section offers a concise overview of the deserialization process of an object when we don’t use a binder, surrogate or the ISerializable interface.
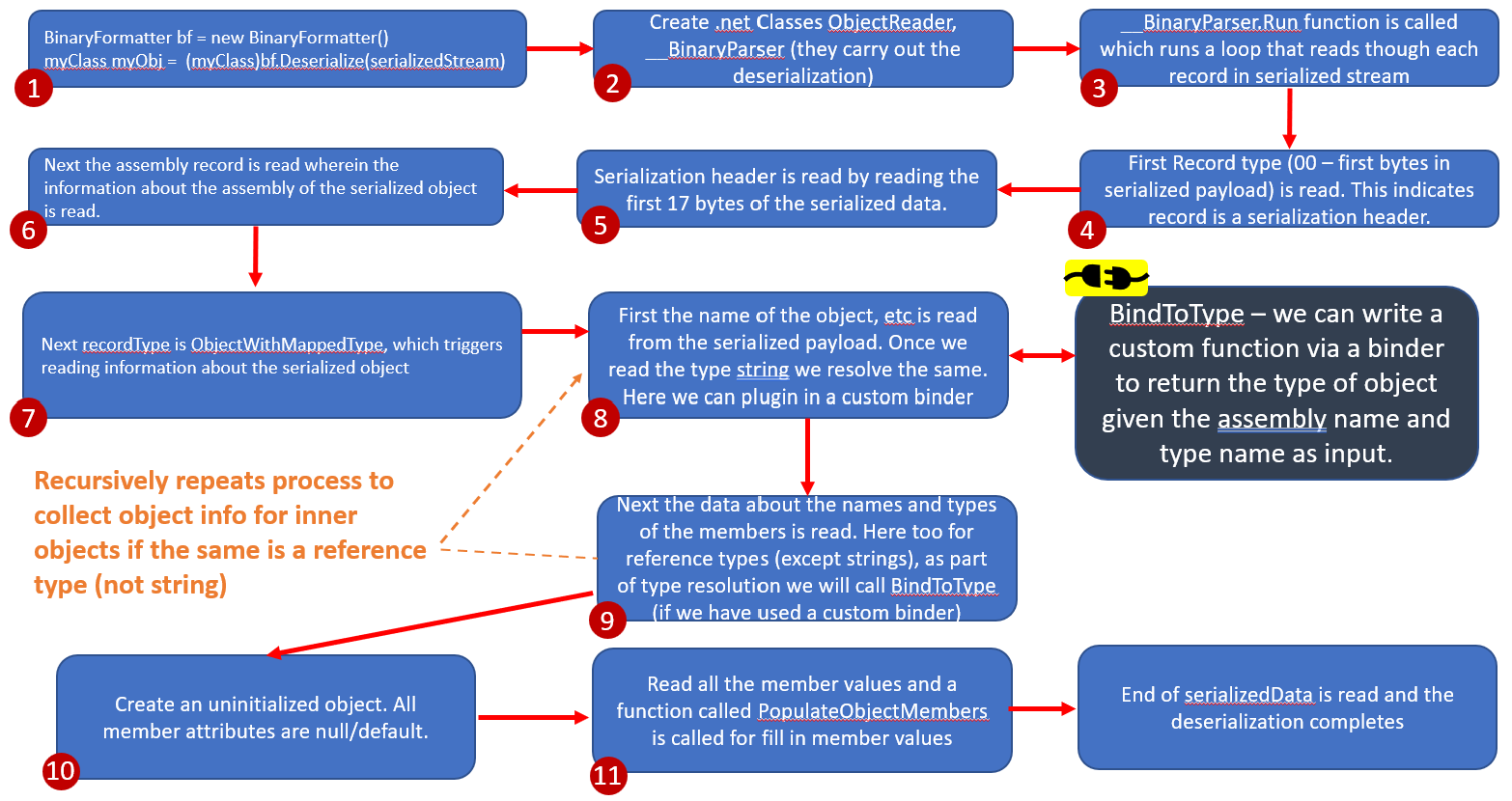
The above diagram elucidates the sequence of steps during deserialization. It’s crucial to note that when employing the binary formatter, the type of the object to be serialized is part of the serialized payload.
The binary formatter identifies this type and proceeds to instantiate an uninitialized object, filling it with the corresponding values. Notably, the object’s constructor is not invoked in this process, at least in the discussed flow (though a constructor does get invoked if the ISerializable interface is used).
An aspect not explicitly illustrated in the diagram, besides surrogates, is the presence of event handlers. These handlers, defined within classes, can be executed once the deserialization of the corresponding object of that class concludes.
I trust this blog has provided clarity on the inner workings of serialization and deserialization within the context of the binary formatter. In the next blog we will look through how the deserialization flow can be exploited to carry out attacks like remote code execution.
References
- Contents of a binary serialized payload
- Binary Serialization (diranieh.com) - Explore different serialization/deserialization approaches supported by the binary formatter.